
Universal CPE (uCPE) is an industry hot topic as it brings more flexibility in the subscription and deployment of value-added services for end-customers through virtualization.
It consists of a single platform running virtual network functions (VNFs) to replace multiple dedicated appliances. The hardware is built using commercial off-the-shelf (COTS) servers, which brings another strong advantage in the global sourcing capabilities of a unique or commonly used hardware platform.
Many industry articles list the benefits of uCPE within the growing trend towards a flexible and programmable network. However, one of the main objections of uCPE from Service Providers is: “will the uCPE meet my customer’s performance requirements?”
This question is valid because network intensive tasks are required for the uCPE including switching between VNFs at the host level. When VNFs are chained, more switching operations are needed. Additionally, performance must be deterministic to avoid facing temporary issues that will be difficult to analyze and troubleshoot.
The price for all-in-one uCPE appliances is very sensitive, and a Telecom Equipment Manufacturer (TEM) starting in the uCPE business cannot afford to build its solution on a platform that won’t match Service Provider’s TCO expectations. I have personally been involved in many of these discussions with TEMs, and understand how critical it is to have the most efficient switching/routing stack to keep the best possible price/performance ratio to be competitive on this market.
Routing is a must-have feature for uCPE. Some TEMs, to optimize the design, take the decision to embed the mandatory vRouter directly in the infrastructure. It has multiple advantages, such as avoiding additional switching operations from/to a dedicated vRouter VNF, but also properly managing end-to-end Quality of Service (QoS) in case congestion happens during the VNF chain.
TEMs may also want to add a low-cost physical CPE design, without virtualization capabilities, based on the same architecture, routing software and management.
This blog post will detail a test that compares the efficiency of a Linux networking stack versus 6WIND’s vRouter stack for uCPE solutions. The test goal is to determine the routing capability of a single Atom C2000 CPU core in a uCPE use case to understand the savings brought by an efficient fast path stack versus Linux. No VNFs are used in this test for the sake of simplicity. The main goal was to showcase a low-cost CPE design based on a COTS server. Please note 6WIND’s vRouter is fully able to combine switching features (by offloading Linux Bridge or Open vSwitch data plane from the kernel) with routing. After the test, we will conclude that 6WIND vRouter is 7X Linux performance for uCPE.
6WIND vRouter: Fast Path Networking Stack for uCPE
6WIND’s networking stack is designed as an acceleration engine for the Linux networking stack, offloading network processing from the Linux stack into what we refer to as our fast path. 6WIND’s fast path runs on a dedicated set of cores (only one in this example). It has very limited impact on the system’s management. Standard Linux commands will be used to configure networking, and we demonstrate that our fast path properly reflects Linux networking stack states. The advantages of such design for uCPE are huge, and summarized below.
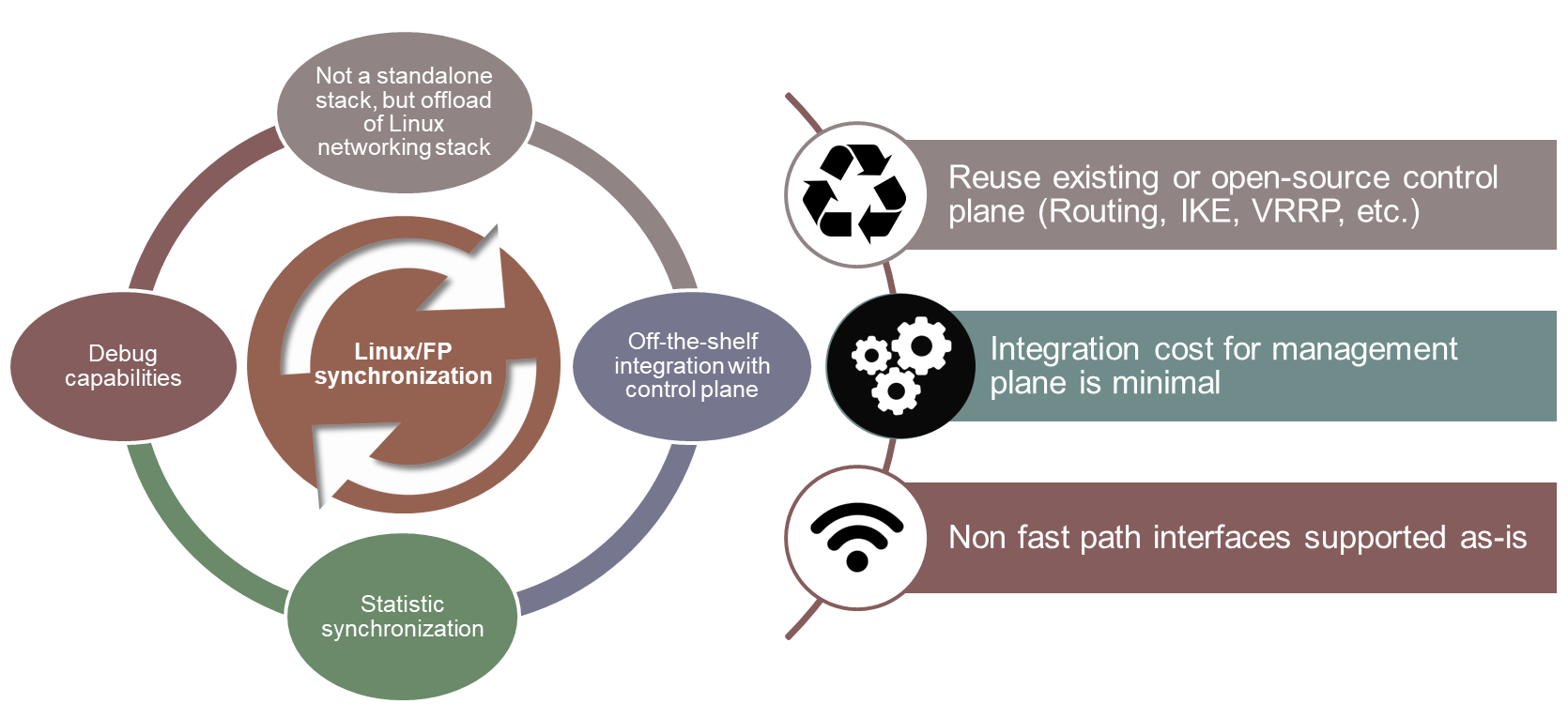
One of the drawbacks with other projects such as OVS-DPDK or VPP is that they are designed as standalone stacks. This makes it very complex to mix Ethernet interfaces natively managed by those technologies with LTE or USB interfaces that may not be usable with those stacks. 6WIND’s vRouter natively supports this mix by design.
uCPE Benchmark: 6WIND vRouter vs Linux
The test was performed using an Intel Atom(TM) CPU C2758 running at 2.40GHz. A single core of this CPU is dedicated to the forwarding plane for testing in the fast path configuration (FP_MASK):
root@alicante:~# fp-conf-tool -D -S
: ${FP_MASK:=1}
: ${FP_PORTS:=’0000:00:14.0 0000:00:14.1 0000:00:14.2 0000:00:14.3′}
Three 1Gbps ports are used as LAN ports, while a single 1Gbps port is used for WAN.
These 4x1Gbps ports are connected to an IXIA to generate the traffic and measure the performance.
1: Let’s start with the uCPE configuration
# Create LAN bridge
brctl addbr lan
brctl addif lan enp0s20f0
brctl addif lan enp0s20f1
brctl addif lan enp0s20f2
# Rename WAN port
ip link set dev enp0s20f3 name wan
# Change MACs
ip link set dev lan address 00:0C:C3:11:22:33
ip link set dev wan address 00:0C:C3:44:55:66
# Interfaces up
ip link set dev enp0s20f0 up
ip link set dev enp0s20f1 up
ip link set dev enp0s20f2 up
ip link set dev lan up
ip link set dev wan up
# IP address on LAN
ip address add 192.168.1.254/24 dev lan
# IP address on WAN
ip address add 172.16.1.254/24 dev wan
# Add NAT on WAN interface
iptables -A POSTROUTING -o wan -j MASQUERADE
# Add 3 fake hosts on LAN
ip neighbor add 192.168.1.1 lladdr 00:0c:c3:11:11:11 dev lan nud permanent
ip neighbor add 192.168.1.2 lladdr 00:0c:c3:22:22:22 dev lan nud permanent
ip neighbor add 192.168.1.3 lladdr 00:0c:c3:33:33:33 dev lan nud permanent
# Add fake neighbor on WAN
ip neighbor add 172.16.1.100 lladdr 00:0c:c3:44:44:44 dev wan nud permanent
# Create a strict priority scheduler on wan egress interface, and shape @ 1Gbps
fp-cli qos-sched-add wan prio 4 rate 1g
# Mark voice traffic as prio 1
iptables -t mangle -A POSTROUTING -m dscp –dscp 0x2e -j MARK –set-xmark 0x1
# Mark video traffic as prio 2
iptables -t mangle -A POSTROUTING -m dscp –dscp 0x0a -j MARK –set-xmark 0x2
2: Let’s dump the fast path states to check everything is properly in sync
We first check the Linux Bridge has been created in the fast path, and the three LAN ports are added to this bridge:
root@alicante:~# fp-cli bridge
Bridge interfaces:
lan-vr0:
nf_call_iptables off:
nf_call_ip6tables off:
enp0s20f2-vr0: master lan-vr0
state: forwarding
features: learning flooding
enp0s20f1-vr0: master lan-vr0
state: forwarding
features: learning flooding
enp0s20f0-vr0: master lan-vr0
state: forwarding
features: learning flooding
We then validate that the IP addresses and routes are synchronized:
root@alicante:~# fp-cli addr4 lan
number of ip address: 1
192.168.1.254 [2]
root@alicante:~# fp-cli addr4 wan
number of ip address: 1
172.16.1.254 [1]
root@alicante:~# fp-cli route4 type all table 254
# – Preferred, * – Active, > – selected
(254) 0.0.0.0/0 [03] NEIGH gw 10.16.18.9 via mgmt0-vr0 (11)
(254) 10.16.18.0/24 [07] CONNECTED via mgmt0-vr0 (12)
(254) 172.16.1.0/24 [40] CONNECTED via wan-vr0 (43)
(254) 192.168.1.0/24 [38] CONNECTED via lan-vr0 (41)
Finally, on the filtering side, we have our NAT rule, and our two classification rules:
root@alicante:~# fp-cli nf4-rules nat
Chain PREROUTING (policy ACCEPT 0 packets 0 bytes)
pkts bytes target prot opt in out source destination
Chain INPUT (policy ACCEPT 0 packets 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets 0 bytes)
pkts bytes target prot opt in out source destination
Chain POSTROUTING (policy ACCEPT 0 packets 0 bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all — any wan anywhere anywhere
root@alicante:~# fp-cli nf4-rules mangle
Chain PREROUTING (policy ACCEPT 0 packets 0 bytes)
pkts bytes target prot opt in out source destination
Chain INPUT (policy ACCEPT 0 packets 0 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets 0 bytes)
pkts bytes target prot opt in out source destination
Chain POSTROUTING (policy ACCEPT 568517349 packets 189865968130 bytes)
pkts bytes target prot opt in out source destination
0 0 MARK all — any any anywhere anywhere MARK set 0x1 DSCP match 0x2e
0 0 MARK all — any any anywhere anywhere MARK set 0x2 DSCP match 0x0a
3: Traffic generated from the IXIA
From the IXIA, I am sending IMIX traffic (64B x 7, 570B x 4, 1518B x 1) from all the interfaces:
Port 1 (LAN) -> Port 4 (WAN):
MAC: 00 0C C3 11 11 11 -> 00 0C C3 11 22 33
IPs: 192.168.1.1 -> 172.16.1.100
UDP: Port 10000 -> Port 10000
DSCP: EF (46)
Rate: 33%
Port 2 (LAN) -> Port 4 (WAN):
MAC: 00 0C C3 22 22 22 -> 00 0C C3 11 22 33
IPs: 192.168.1.2 -> 172.16.1.100
UDP: Port 20000 -> Port 20000
DSCP: AF Class 1 Low Drop Precendence (10)
Rate: 33%
Port 3 (LAN) -> Port 4 (WAN):
MAC: 00 0C C3 33 33 33 -> 00 0C C3 11 22 33
IPs: 192.168.1.3 -> 172.16.1.100
UDP: Port 30000 -> Port 30000
DSCP: 0
Rate: 38% (sending a little more than 1G from LAN to WAN so that traffic is dropped by QoS)
Port 4 (WAN) -> Port 1 (LAN):
MAC: 00 0C C3 44 44 44 -> 00 0C C3 44 55 66
IPs: 172.16.1.100 -> 172.16.1.254
UDP: Port 10000 -> Port 10000
DSCP: 0
Rate: 33%
Port 4 (WAN) -> Port 2 (LAN):
MAC: 00 0C C3 44 44 44 -> 00 0C C3 44 55 66
IPs: 172.16.1.100 -> 172.16.1.254
UDP: Port 20000 -> Port 20000
DSCP: 0
Rate: 33%
Port 4 (WAN) -> Port 3 (LAN):
MAC: 00 0C C3 44 44 44 -> 00 0C C3 44 55 66
IPs: 172.16.1.100 -> 172.16.1.254
UDP: Port 30000 -> Port 30000
DSCP: 0
Rate: 33%
4: Starting the traffic
I start traffic from LAN to WAN to establish the conntracks:
root@alicante:~# conntrack -L
udp 17 28 src=192.168.1.1 dst=172.16.1.100 sport=10000 dport=10000 [UNREPLIED] src=172.16.1.100 dst=172.16.1.254 sport=10000 dport=10000 mark=0 use=1
udp 17 27 src=192.168.1.3 dst=172.16.1.100 sport=30000 dport=30000 [UNREPLIED] src=172.16.1.100 dst=172.16.1.254 sport=30000 dport=30000 mark=0 use=1
udp 17 27 src=192.168.1.2 dst=172.16.1.100 sport=20000 dport=20000 [UNREPLIED] src=172.16.1.100 dst=172.16.1.254 sport=20000 dport=20000 mark=0 use=1
…
Those are synced in the fast path:
root@alicante:~# fp-cli nfct4
Number of flows: 8/1024
Flow: #2
Proto: 17
Original: src: 192.168.1.2:20000 -> dst: 172.16.1.100:20000
Reply: src: 172.16.1.100:20000 -> dst: 172.16.1.254:20000
VRF-ID: 0 Zone: 0 Mark: 0x0
Flag: 0x45, hitflag: 0x01,
snat: yes, dnat: no,
assured: no, seen_reply: no,
unreplied: yes, expected: no,
update: yes, end: no
Stats:
Original: pkt: 24008990, bytes: 3762809704
Reply: pkt: 0, bytes: 0
Flow: #3
Proto: 17
Original: src: 192.168.1.3:30000 -> dst: 172.16.1.100:30000
Reply: src: 172.16.1.100:30000 -> dst: 172.16.1.254:30000
VRF-ID: 0 Zone: 0 Mark: 0x0
Flag: 0x45, hitflag: 0x01,
snat: yes, dnat: no,
assured: no, seen_reply: no,
unreplied: yes, expected: no,
update: yes, end: no
Stats:
Original: pkt: 27154256, bytes: 534004408
Reply: pkt: 0, bytes: 0
..
Flow: #37
Proto: 17
Original: src: 192.168.1.1:10000 -> dst: 172.16.1.100:10000
Reply: src: 172.16.1.100:10000 -> dst: 172.16.1.254:10000
VRF-ID: 0 Zone: 0 Mark: 0x0
Flag: 0x45, hitflag: 0x01,
snat: yes, dnat: no,
assured: no, seen_reply: no,
unreplied: yes, expected: no,
update: yes, end: no
Stats:
Original: pkt: 24542609, bytes: 3939691804
Reply: pkt: 0, bytes: 0
I am then sending the return traffic, from WAN to LAN @ 1Gbps with iMIX packets.
Conntracks are now marked as assured, meaning the connection tracking table has seen the reply:
root@alicante:~# conntrack -L
udp 17 169 src=192.168.1.1 dst=172.16.1.100 sport=10000 dport=10000 src=172.16.1.100 dst=172.16.1.254 sport=10000 dport=10000 [ASSURED] mark=0 use=1
udp 17 169 src=192.168.1.3 dst=172.16.1.100 sport=30000 dport=30000 src=172.16.1.100 dst=172.16.1.254 sport=30000 dport=30000 [ASSURED] mark=0 use=1
udp 17 169 src=192.168.1.2 dst=172.16.1.100 sport=20000 dport=20000 src=172.16.1.100 dst=172.16.1.254 sport=20000 dport=20000 [ASSURED] mark=0 use=1
And synced in the fast path:
root@alicante:~# fp-cli nfct4
Number of flows: 7/1024
Flow: #2
Proto: 17
Original: src: 192.168.1.2:20000 -> dst: 172.16.1.100:20000
Reply: src: 172.16.1.100:20000 -> dst: 172.16.1.254:20000
VRF-ID: 0 Zone: 0 Mark: 0x0
Flag: 0x15, hitflag: 0x01,
snat: yes, dnat: no,
assured: yes, seen_reply: no,
unreplied: no, expected: no,
update: yes, end: no
Stats:
Original: pkt: 63093026, bytes: 4003412860
Reply: pkt: 15317000, bytes: 794127526
Flow: #3
Proto: 17
Original: src: 192.168.1.3:30000 -> dst: 172.16.1.100:30000
Reply: src: 172.16.1.100:30000 -> dst: 172.16.1.254:30000
VRF-ID: 0 Zone: 0 Mark: 0x0
Flag: 0x15, hitflag: 0x01,
snat: yes, dnat: no,
assured: yes, seen_reply: no,
unreplied: no, expected: no,
update: yes, end: no
Stats:
Original: pkt: 72220564, bytes: 2780797232
Reply: pkt: 15316878, bytes: 791419450
Flow: #37
Proto: 17
Original: src: 192.168.1.1:10000 -> dst: 172.16.1.100:10000
Reply: src: 172.16.1.100:10000 -> dst: 172.16.1.254:10000
VRF-ID: 0 Zone: 0 Mark: 0x0
Flag: 0x15, hitflag: 0x01,
snat: yes, dnat: no,
assured: yes, seen_reply: no,
unreplied: no, expected: no,
update: yes, end: no
Stats:
Original: pkt: 63626752, bytes: 4176151352
Reply: pkt: 15317006, bytes: 787949596
QoS is enabled and doing its job (dropping some packets for class 4, as the total traffic from LAN to WAN is above 1Gbps):
root@alicante:~# fp-cli qos-stats-reset
root@alicante:~# fp-cli qos-stats non-zero
sched iface=wan-vrf0 [1]:
| enq_ok_pkts:374981
| enq_drop_qfull_pkts:19361
| xmit_ok_pkts:375000
| class classid=0x1 [9]:
| | enq_ok_pkts:125066
| | xmit_ok_pkts:125074
| class classid=0x2 [10]:
| | enq_ok_pkts:125075
| | xmit_ok_pkts:125076
| class classid=0x3 [11]:
| class classid=0x4 [12]:
| | enq_ok_pkts:124859
| | enq_drop_qfull_pkts:19361
| | xmit_ok_pkts:124877
5: Results
Using 6WIND’s vRouter networking stack, I was able to sustain the 1Gbps bi-directional with IMIX traffic and all features enabled on 1 single core.
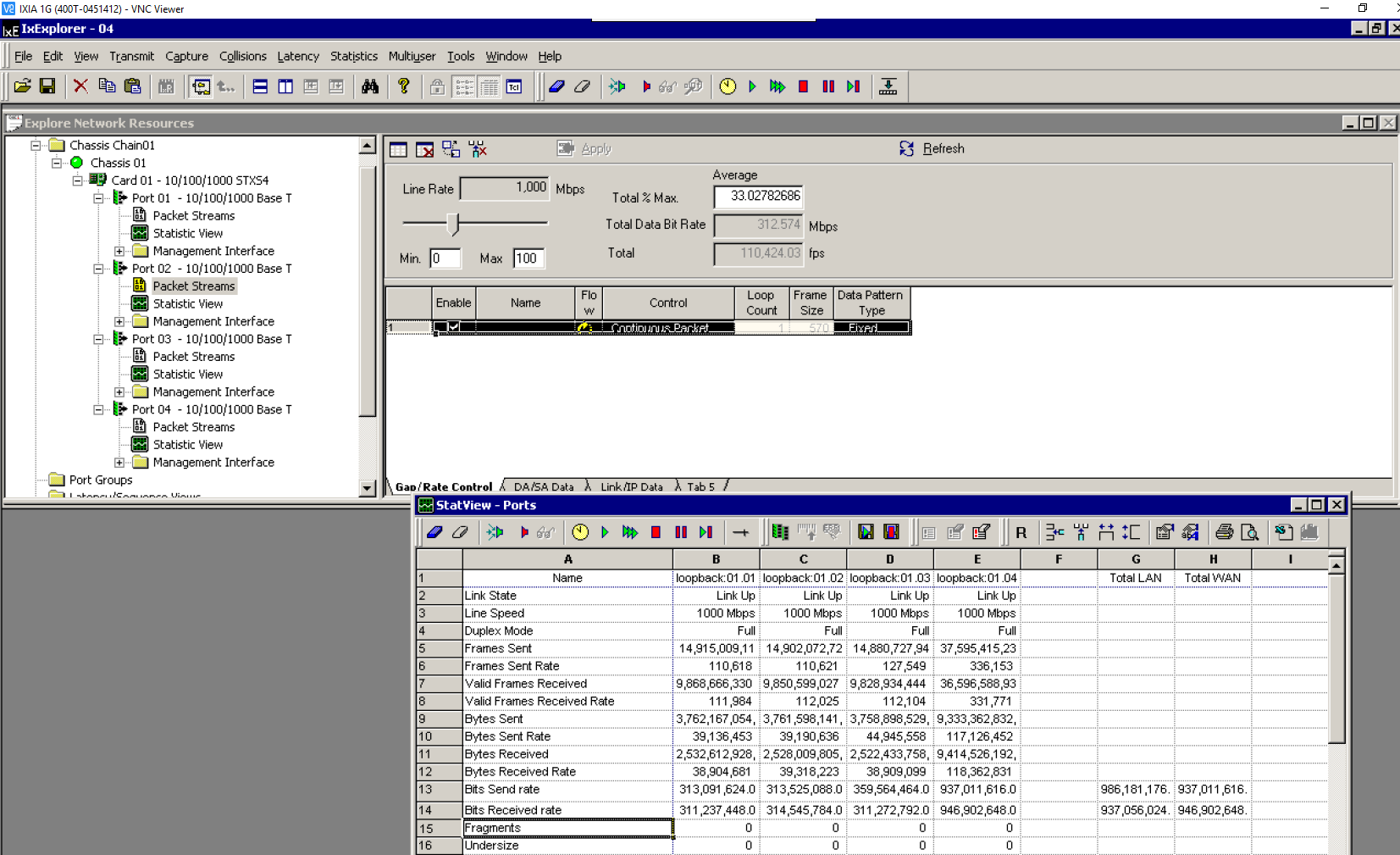
Data plane CPU usage is showing 100%, but may still have some margin thanks to packet bulking efficiency:
root@alicante:~# fp-cpu-usage
Fast path CPU usage:
cpu: %busy cycles cycles/packet cycles/ic pkt
1: 100% 480029592 2361 0
average cycles/packets received from NIC: 2361 (480029592/203297)
I was not losing any packets during the test due to CPU load, as the hardware queues were reporting no loss:
root@alicante:~# ethtool -S wan | grep miss
rx_missed_errors: 0
rx_missed_packets: 0
6: Same test with Linux
It is interesting to understand how fast 6WIND’s vRouter is compared to Linux.
Thus, the same test was done by stopping 6WIND’s fast path, and still using a single core to perform the network processing. For this, I pinned all network IRQs to the same core that the fast path was previously using.
The configuration of the device is exactly the same, with the exception of the QoS scheduler configuration. The fast path does not support Linux TC synchronization, but has its own dedicated API for QoS. Equivalent Linux TC configuration looks like:
# Create a SP scheduler on wan egress interface
tc qdisc add dev wan root handle 1: prio bands 4 priomap 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
tc filter add dev wan parent 1: protocol all prio 1 handle 0x1 fw classid 1:1
tc filter add dev wan parent 1: protocol all prio 1 handle 0x2 fw classid 1:2
The result is totally different: out of the 2Gbps sent by the IXIA, only 300Mbps is successfully processed by Linux, while the 6WIND fast path was able to sustain the full 2Gbps.
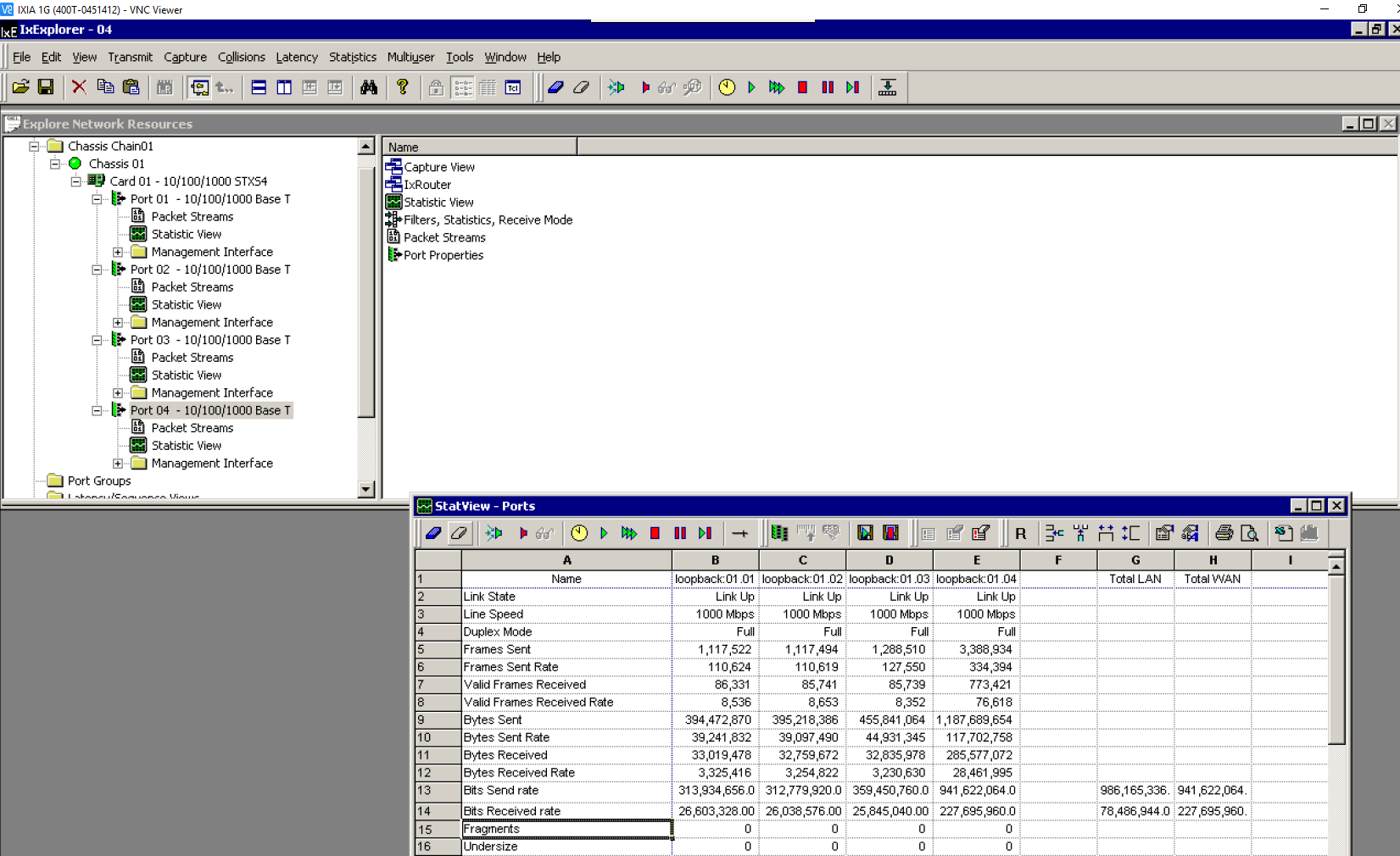
Conclusion: 6WIND vRouter is 7X Linux Performance for uCPE
The first conclusion of our benchmark is that without an efficient networking stack the number of COTS server cores needed to sustain the target performance for uCPE appliances may be too high for the targeted TCO. 6WIND’s vRouter networking stack, as demonstrated in this benchmark, allows customers to pick an entry level 2 core CPU to build a physical CPE with good performance, while a 4 core CPU running a Linux stack wouldn’t even be close to the same performance.

When adding VNFs, the efficiency of the host routing stack will be even more important, as additional switching operations from/to the VNFs will be combined with routing. Thus, the CPU cycles saved by the efficient routing stack will save more compute for the VNFs themselves.
If you are designing a uCPE solution and looking to increase performance while saving costs, contact us today to request an evaluation of 6WIND vRouter.

Nicolas Harnois is Pre-sales Manager at 6WIND.



