 Moore’s Law observes that the number of transistors within CPUs doubles every eighteen months. In other words, the typical system performance doubles every eighteen months. During the 20th century this result was achieved using several strategies: reducing the transistor size, increasing the pipeline depth and increasing the oscillator frequency.
Moore’s Law observes that the number of transistors within CPUs doubles every eighteen months. In other words, the typical system performance doubles every eighteen months. During the 20th century this result was achieved using several strategies: reducing the transistor size, increasing the pipeline depth and increasing the oscillator frequency.
However this approach had limitations; the frequency cannot be increased while keeping a reasonable power consumption and increasing the pipeline depth will ultimately reduce the CPU performance.
In order to keep increasing performance, the transistor size continued to decrease, frequency remained stable and multiple cores on the same CPU started to appear.
As high speed networking now uses 10/40/100+ Gbps connectivity, a Virtual Border Router, or vRouter, needs to process this traffic in parallel using these multiple cores to maximize performance.
Packets received on one port must be dispatched to the different cores. Techniques such as round robin distribution will lead to packet disordering, which will reduce performance and increase the memory usage on connection endpoints.
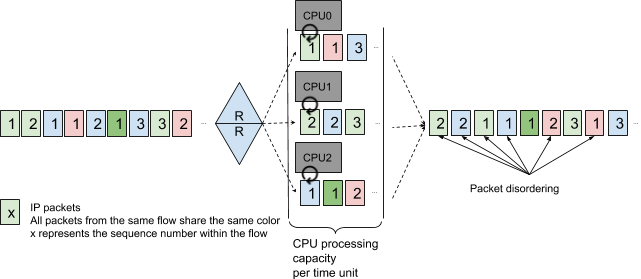
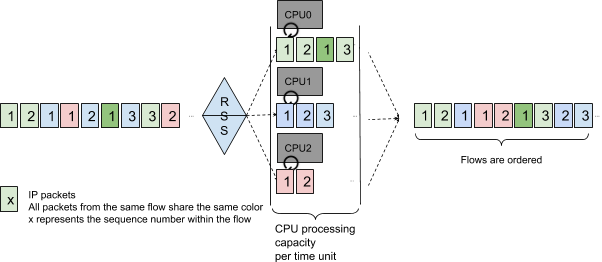
Receive Side Scaling (RSS) is a mandatory feature when processing packets on a multicore CPU system.
Using RSS with the NIC hashes the packets to select the processing core:
- Packets are dispatched on multiple cores, reducing the risk of having an idle core
- As all packets from the same flow are processed on the same core, the CPU cache likely contains information to process the packet efficiently
- Packet ordering within a flow is guaranteed
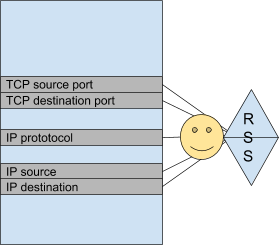
RSS hash is performed by the NIC on predefined fields of the packet, for example IP address source and destination, the IP protocol and TCP source and destination port.
It means the NIC must be able to parse the packet and understand where these fields are present.
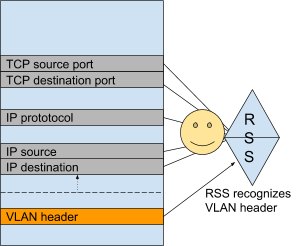
The Problem
Most NICs can handle simple operations such as the identification of a VLAN header and its impact on the location of hashable fields.
However some protocols are not handled such as PPPoE and MPLS.
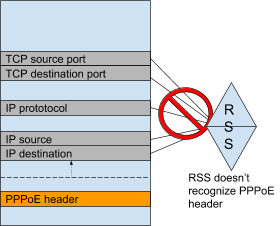
This results in all packets with PPPoE headers being processed by the same core; as a consequence the vRouter performance will be limited to this core performance.
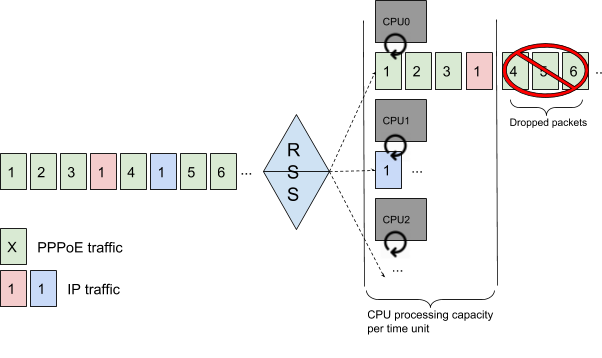
In this example, most of the traffic is PPPoE. As it cannot be recognized as “hashable” by the NIC, each PPPoE packet will be processed by the first CPU.
IP traffic can be hashed correctly. Please note the result of the hash depends only on the packet content, so even if CPU0 is loaded it can receive other traffic besides PPPoE.
The result is that CPU0 is completely overloaded, leading to packet drops while CPU1 and CPU2 are almost idle. The entire system performance is limited to CPU0 processing capacity.
6WIND Offers vRouter Solutions
There are multiple ways to deal with such limitation.
One possible option is to implement the ability to recognize different kinds of traffic at the NIC level. This requires additional configuration but most importantly each driver implements its own features.
As a reference check this feature support matrix; while RSS is implemented by most drivers, advanced flow management such as Flow Director or Flow API are far less frequent.
This is a problem if you want to have a generic solution not depending on NIC drivers.
A generic approach is to use a software pipeline approach: one CPU will be responsible for receiving all traffic and dispatching it to other CPUs.
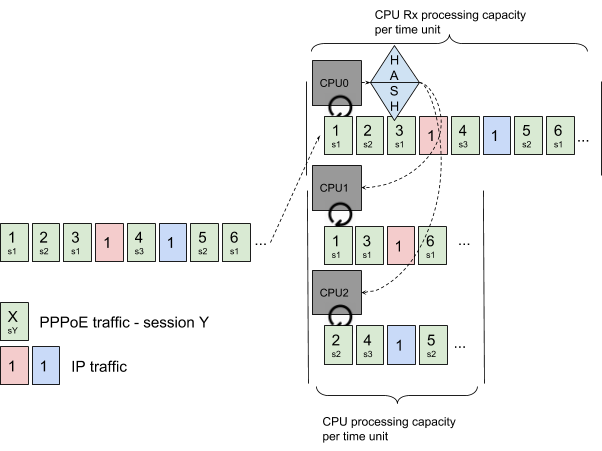
CPU0 receives all traffic and dispatches it according to its own policy. It can parse packets entirely; in this example it uses PPPoE Session ID (s1, s2, s3) to assure PPPoE packet ordering.
As its operation is simpler, CPU0 Rx processing capacity is more important than the processing capacity of CPU1 and CPU2, and not limiting the system performance.
CPU0 dispatches PPPoE Session s1 to CPU1 and PPPoE sessions s2 and s3 to CPU2.
Conclusion
This pipeline approach is totally generic and is flexible enough to accomodate all kinds of traffic: PPPoE, MPLS, QinQ and even encapsulated traffic such as IPsec tunnels, GTP, L2TP, etc. It guarantees good performance as a typical Xeon single core is able to manage 10M+ packets per second (PPS), and packet ordering is maintained and preserves application performance.
The load-balancer plug-in implementation described in the first part this blog will depend on the protocol that needs to be processed: PPPoE will use PPP Session Identifier, GTP will use Tunnel Endpoint Identifier, IPsec will use Security Policy Index etc. As a consequence, multiple flows are required in order to properly load-balance the traffic.
In the second part of this blog, we’ll detail how 6WIND Turbo IPsec vRouter handles more tricky situations such as dealing with 100 Gbps traffic within a single IPsec tunnel. So stay tuned for more on IPsec in Part 2.
Contact us today to discuss the performance requirements for your vRouter deployment scenarios. We are happy to share our expertise.
Damien Routier is the Support Team Manager at 6WIND. 



